Posted on 2015年7月7日(火) 04:29
最近「ComicGlassのソートがWindowsの並びと違う」とご意見を頂きました。
WindowsXP以降ではファイル名のソート順が数値などを解釈する自然な並びになるようになっています。
よって単純なコードの比較とは違う結果になります。
よく説明されるのは、
20string
2string
3string
というソート順だったのが
2string
3string
20string
という感じになることでしょうか。
WindowsであればStrCmpLogicalW()というAPIを呼び出すとこのソートが行われます。
Windows以外の環境でこのソートを再現する方法は、検索するといくつか提案されていますが、どうも結果が違います。
公式な仕様が見つかればいいんですが、どうも見つかりません。
そこで、それを再現すべくそもそもWindowsがどのようにソートしているか実験してみました。
(特に海外のサイトの情報はUnicode文字に関する配慮がほとんどされてない事が多いので)
結論から言うと、StrCmpLogicalWを再現するのって無理ゲーなんじゃないかと・・・。
いい方法あったら是非教えてください。
とりあえず、以下調査結果でございます。
・StrCmpLogicalWは記号、数値、その他文字の順で並ぶ
ASCIIやUnicodeでは「!」は「0~9」より前にあるが「;」などは数値より後です。
しかしながらWindowsでは「;」などの記号も数値より前に並びます。
(Unicodeコード順)
!test.txt
0test.txt
;test.txt
(Windows)
!test.txt
;test.txt
0test.txt
というわけで、その文字が「記号」であるか「数値」であるか「その他文字」であるかを区別しているようです。
そこで問題になるのが、何が記号で何が記号でないか。
(記号になる例)
!
;
®
µ
§
»
★
(記号にならない一例)
¼
À
うーん。規則性がわからん。
プログラムを組んでStrCmpLogicalWで実際に試してみたのですが、かなり後ろの方のコードまで記号扱いになるものとと文字扱いになるものが入り乱れています。
どうもUnicodeコンソーシアムが規定するUNICOD文字一覧表に記号かどうかの情報があるようです。
つまりUnicodeとして記号かどうかで判断されており、それは規則性などなく全一覧を知らないとどうにもならない。
まぁ、それだけなら全コードの情報を持っておけばいいのですが・・・
・・・しかし!
Windowsが知らない新しいUnicodeは正しく解釈していないような気がします・・・。
例えばU+2639(☹)、U+263A(☺)、U+263B(☻)は記号扱いですが、その他顔文字は記号になりません。
もしかしたらWindowsではサロゲートペアが正しく処理されていないだけかもしれません・・・。
これは心が折れますね・・・!
・StrCmpLogicalWは全角の記号も半角と記号と同じ扱いになる
同じ記号の場合は全角の方が後になる。
・・・ってことは正準等価性を使った正規化してるんでしょうかね?
その説を支持する結果として「»」が「§」よりも前に並ぶんですよね。コードは後ろなのに。
しかし後述しますが、数値で混在すると別々に評価されるっぽい。つまり単純に先に正規化しても駄目と・・・。
・StrCmpLogicalWは数字が並んでいる場合はまとめて1つの意味付けがされる
0001.txt
2.txt
003.txt
これはファイルに0から順に名前つけて桁が増えた時に変な順番になるのを防げます。
・StrCmpLogicalWは20桁以上の数値は数値として扱わない
符号なし64bitで表せる値の最大値は18,446,744,073,709,551,616で20桁なので、20桁目からオーバーフローします。
よって、Windowsも64bit演算で扱える最大値の19桁まで取り扱うようになっていると思われます。
これは実装が楽で助かります。
・StrCmpLogicalWは全角の0~9も数字として扱われる
・ただし半角全角混在の場合はそうならない。何故だ・・。
情報求む・・・・!
とりあえずASCIIコードにある記号だけ記号として解釈し、数値は19桁まで数値として認識する、という方法でだいたい近い結果にはなります。一致はしませんが。
Posted on 2014年9月30日(火) 23:40
・・・タイトルのようなソフトをリリースしましたのでお知らせします。
リリースしたのは少し前ですが、記事にしていませんでしたので。
最近のWindowsではソフトウエアでボリュームのミラーが作れるようになり、HDDの故障に備えることができるようになりました。
Windowsのミラーの良いところは何より扱いやすいことです。BIOS画面一切さわる必要ありませんし。
しかし、いざ障害が起きた時にそれを知る手段がイマイチないのが問題でした。
というわけでステータスが変わったらメールするソフト作ってみました。
こちらでございます。
http://arinkosoft.com/download/asvolumestatuschecker/
Posted on 2014年9月8日(月) 23:53
UTF-8って素晴らしいですよね。
unicodeは元々、世界中の全ての文字を16bitで表現するという英語圏以外の人からすればあまりに愚かな試みからスタートしましたが、もちろん破綻。
16bitを使いながら、サロゲートペアを使って16bit以上のコードも表現するようになりました。
結局サロゲートペアが必要な時点でUTF-16は欠点ばかりのものとなってしまいました。
最近よく使われるのはUTF-8です。ASCIIコードと互換性が保ちやすく大変便利ですね。
UTF-8は結局のところUTF-32をシリアライズしただけのものなんですが、へぇよく考えてるなぁという感じなのです。
任意のバイトストリームから混同せずに文字列を取り出せます。
ただ欠点もあって、色々処理をするときに文字ごとに長さが違うので厄介です。
そこでUTF-8から32bit表現(UTF-32)に変換するコードを書いてみました。
プログラムの内部的にはUTF-32を使うと捗りますので。
このようなUTF-8の欠点はサロゲートペアがある時点でUTF-16でも同様なんですが、サロゲートペアはあまり出てこないので無視してしまってる駄目な処理系もあるような気がします。
なお、セキュリティの観点からはUTF-8の冗長表現が問題になることもあります。
本来ASCIIコードである文字でももっと大きなバイス数で表現することが出来てしまうので不正文字チェックを抜けてしまうということです。
例えば0xC0 0xAF(11000000 10101111)は、2バイトのUTF-8として扱うと[101111]の部分がデータになりますので、0x2F(バックスラッシュ)と等価になります。
つまりより小さいバイトのコードは大きなバイト数でも表現出来てしまうため、単純チェックだとすり抜けるということです。
仕様ではこのようなバイト列は不正なUTF-8バイト列としなければなりません。
また5バイトと6バイトのUTF-8も現在ではUnicodeとしては不正とされていますがISO/IEC 10646では存在しています。
以下のコードではそのような不正なUTF-8もそのまま変換します。
unsigned long utf8ToUtf32(unsigned char *input, int *bytesInSequence)
{
unsigned char c1, c2, c3, c4, c5, c6;
*bytesInSequence = 1;
if (!input)
{
return 0;
}
//0xxxxxxx (ASCII) 7bit
c1 = input[0];
if ((c1 & 0x80) == 0x00)
{
return c1;
}
//10xxxxxx high-order byte
if ((c1 & 0xc0) == 0x80)
{
return 0;
}
//0xFE or 0xFF BOM (not utf-8)
if (c1 == 0xfe || c1 == 0xFF )
{
return 0;
}
//110AAAAA 10BBBBBB 5+6bit=11bit
c2 = input[1];
if (((c1 & 0xe0) == 0xc0) &&
((c2 & 0xc0) == 0x80))
{
*bytesInSequence = 2;
return ((c1 & 0x1f) << 6) | (c2 & 0x3f);
}
//1110AAAA 10BBBBBB 10CCCCCC 4+6*2bit=16bit
c3 = input[2];
if (((c1 & 0xf0) == 0xe0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80))
{
*bytesInSequence = 3;
return ((c1 & 0x0f) << 12) | ((c2 & 0x3f) << 6) | (c3 & 0x3f);
}
//1111 0AAA 10BBBBBB 10CCCCCC 10DDDDDD 3+6*3bit=21bit
c4 = input[3];
if (((c1 & 0xf8) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x07) << 18) | ((c2 & 0x3f) << 12) | ((c3 & 0x3f) << 6) | (c4 & 0x3f);
}
//1111 00AA 10BBBBBB 10CCCCCC 10DDDDDD 10EEEEEE 2+6*4bit=26bit
c5 = input[4];
if (((c1 & 0xfc) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80) &&
((c5 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x03) << 24) | ((c2 & 0x3f) << 18) | ((c3 & 0x3f) << 12) | ((c4 & 0x3f) << 6) | (c5 & 0x3f);
}
//1111 000A 10BBBBBB 10CCCCCC 10DDDDDD 10EEEEEE 10FFFFFF 1+6*5bit=31bit
c6 = input[5];
if (((c1 & 0xfe) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80) &&
((c5 & 0xc0) == 0x80) &&
((c6 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x01) << 30) | ((c2 & 0x3f) << 24) | ((c3 & 0x3f) << 18) | ((c4 & 0x3f) << 12) | ((c5 & 0x3f) << 6) | (c6 & 0x3f);
}
return 0;
}
Posted on 2014年3月23日(日) 02:03
かつて、LinuxからSambaを使ってWindowsのファイル共有にアクセスすると、文字コードの変換の問題で大変苦労しました。
時代は流れ、LinuxでもWindowsでもUnicodeが標準になりました。
というわけで、一般的にSMBを使う分には文字コードで苦労することはほぼなくなりました。
しかし・・・。
とりあえず以下の画像をご覧ください。
これはWindows8のエクスプローラーの画面です。
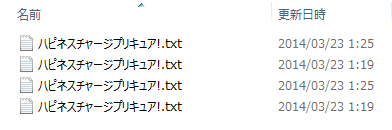
何かおかしいところにお気づきでしょうか。
おかしいですよね。
いいおっさんがプリキュア・・・じゃなくて、同一のファイル名が同じフォルダに存在しています。
実はこれ、「ピ」と「プ」の文字がUNICODEの結合文字列になっています。
通常、Windowsで「プリキュア」と入力した場合、「プ」の文字はU+30D7になります。
しかしMacOSで「プリキュア」と(ファイル名として)入力した場合、「プ」の文字はU+30D5 U+309Aになります。
U+30D5は「フ」です。
U+309Aは半濁点記号です。
つまり、「フ」+「゜」の合成で表現されます。
(なお、ここに書いた「゜」はU+309Cで、合成用ではなくそういう1文字ですので念のため)
Unicodeではこのような複数の表現方法があります。
混ざってる何かと困るので、普通は同一コードになるように正規化して扱います。
合成した方を使うのをNFC(Normalization Form Canonical Composition)、分解した方を使うのをNFD(Normalization Form Canonical Decomposition)と言います。
さて、最初の画像のファイル名ですが、「パ」と「プ」の表現方法を結合文字列、合成文字、混ぜてあります。
結果として4パターンの同名ファイル名が出来てしまったわけです。
何故かWindowsは上記のような状態を許してくれます。
許しているというか、初期の頃になんの正規化もせず扱ってしまったため、以後もそのままになっているんだと思います。(憶測)
さて、一方MacOSですが、上記のようなNFD,NFCの混在を許してくれません。
必ずNFDライクな正規化をされます。(正確にNFDでないのがまた困るんですが・・・)
iOSも一緒です。
よってファイル共有をすると大変困ります。
SMBには明確な仕様がない(もしかしたらあるかもしれなけど、ドキュメント読む限り発見できず)。
おそらくWindowsなのでNFCのUTF16 Little endianなんでしょうが、NFDでもプロトコルとしては問題なく(というかノータッチで)動きます。
さて、どう実装するのが正解なのでしょうか。
困りました。
Posted on 2014年3月21日(金) 23:57
VisualStudio2013では、デフォルトの設定でWindowsXPが切り捨てられています。
フレームワークのバージョンとかでなく、素のWindowsAPIのみを利用していても起動できません。
さすがにもうWindowsXPはサポートしなくても良いのかもしれませんが、Windows2003ServerはWindowsXPと同じ扱いですので、WindowsXPで起動できないとWindows2003Serverでも起動できません。
(Windows 2003Serverは15年7月くらいまでサポート期間があります・・・)
以下の設定を変更すると起動できるようになります。
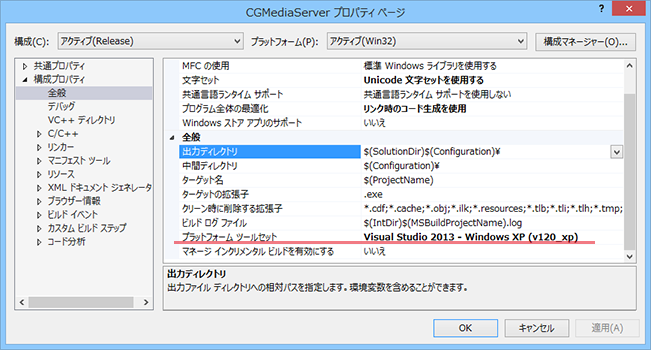
もはや動作確認環境もなく、なかなか気づきにくいので気をつけないといけませんね。
・・・しかしVisualStudio高いよねーー。。
自分の作るWindowsアプリケーションは本当に素のC++で書いているので別にどんなコンパイラでもコンパイルできるんですよね。だから高く感じますが・・・
しかし、VisualStudio2013のエディタはかなり良くなりました。エディタとして買ってます。
Posted on 2014年1月23日(木) 00:02
Windowsでマイネットワークを開くと近くのコンピュータが自動的に表示されます。
これは単純にブロードキャストしてそれぞれが応答をするのではなく、バックアップブラウザを持っているホストに問い合わせをすることで実現しています。
バックアップブラウザはLAN上のコンピュータが自動的に選定されて、どれかがなります。
OSのバージョンによって優先度が決まっていたりしますが、問い合わせるだけなのでその部分はあまり気にしないことにします。
さて、これを実装しようとすると結構面倒で、
1.バックアップブラウザの検索
2.バックアップブラウザからブラウザリスト(ホスト一覧)の取得
と2段階を踏む必要があります。
1はブロードキャストで問い合わせ(GetBackup Request)をすると、バックアップブラウザが応答(GetBackup Response)を返してくれます。
ここで一つ重大な問題があります。
問い合わせは当然ながらIPで行っているわけですが、元はNetBIOSのため、バックアップブラウザが自分に対して応答を返すときに、名前解決を要求してきます。
よってNBNSの問い合わせに応答できるように実装しておかなければなりません。
(IPで送ってるんだからそのアドレスに返してよ・・と思いますがそうはなっていません)
これは本来であればOSの機能なので、アプリで実装してしまうと、他のアプリと同時にポートをBINDしたときに問題が起こりそうですね。
次に2ですが、これはSMBと同じです。
しかし、ダイレクトホスティング(ポート445番)では挙動が不安定でした(Windows7で確認)。
ちゃんとNetBIOSセッションサービスを利用すると安定して取得できます。謎です。
さて、この方法ですと、ワークグループ名の指定が必要です。
また何かしらの理由でバックアップブラウザが存在しないとホスト一覧を取得できません。
以下は禁じ手だと思うのですが、GoodReaderの実装がそうなっていたので紹介しておきます。
確実な方法ですが、ポートスキャンがちょっと攻撃っぽいので今のところComicGlassでは非採用にしました。
1.ネットワークのサブネットマスクからネットワークアドレスとホストアドレスを分離します。
2.全てのホストアドレスのTCP/445番ポートに対して接続を試みます。(つまりポートスキャン)
3.接続できたら、セッションセットアップの途中までやります。途中というのは相手のホスト名が判明するところまでです。(認証の途中)
4.ホスト名(NetBIOS名)が取得できたら切断しちゃいます。
とりあえず上記の方法であればブラウジング機能に頼らずホストを検出できます。ただし同じサブネットの中のみ。
(ポートスキャンしているから当然といえば当然ですが・・・)
Posted on 2014年1月21日(火) 22:36
今回はただの愚痴ですが・・・。
SMB/CIFSの仕様をみると、データの途中にいきなり可変長データが入っていたりします。
さらにpaddingがいたるところに出てきます。
また、変数は存在するものの、実際のところどういう値にしていいのか、定数としてどんなものがあるのかわからないことが多々あります。
そんなときはプロトコルアナライザです。
WindowsServer系ならばリソースキットで利用できますが、WireSharkなんかも便利です。
そして、絶対あったほうが良いもの・・。
それはポートミラーリング、またはポートモニタリング機能がついたスイッチングハブです。
完全なリピータハブがあればそれでもいいですが、おそらく10BASE-Tの時代のものしか無いと思うので・・・。
数年前までは何万円もしましたが、今では1万円を切る商品もあるみたいです。
Posted on 2013年12月13日(金) 02:23
Windows関連情報は運用を目的にしたものが多く、コーディング例はあんまり聞かないのでメモ的に書いておきます。
SMBの認証にはLM認証、NTLMv1認証、NTLMv2認証、Kerberos認証のいずれかを使います。
Kerberos認証は鍵交換でActiveDirectly環境想定のものなので除外。
LM認証はNTLMv1認証はだいぶ古いにもかかわらずつい最近まで使われていましたがWindows7からはデフォルト無効になっているようなのでこちらも使わない方針で行きます。
ようするに面倒なのでNTLMv2だけ対応します。
あと、まず非対応ということはあり得ないので、Unicodeだけ対応します。
さて、NTLMは「NT LAN Manager Authentication Protocol」のことらしいです。
Microsoftの仕様書名は[MS-NLMP]です。
基本的には認証情報をバイト列に並べているだけなので仕様書を読みながら実装すればなんとか出来ます。
SMB/CIFSがアライメントやら謎のpaddingやらとても実装しにくいのに比べると可変長データをpayloadにまとめているので少しだけ気楽です。
クライアント側で生成する必要があるのは、NEGOTIATE_MESSAGEとAUTHENTICATE_MESSAGEです。
前者は本当に必要な情報を連結してバイト列にしているだけなので楽勝。それでも実際実装してみると一発ではなかなか思い通りにならないのですが・・・。
後者のAUTHENTICATE_MESSAGEもほとんど同じですが、NEGOTIATE_MESSAGEに対してサーバから返されたCHALLENGE_MESSAGEに含まれる情報を使ってチャレンジレスポンスを計算する必要があります。
それがNTLMv2なわけですね。
AUTHENTICATE_MESSAGEのうち、計算が必要なのはNTLMv2 Responseというフィールドです。
といっても、使うのはmd4とmd5だけなんですね。
試行錯誤の結果正しい結果を出せるようになったのでメモ。
入力
・ドメイン(大文字のみ,UTF16LittileEndian)
・ユーザ名(大文字のみ,UTF16LittileEndian)
・パスワード(UTF16LittileEndian)
※ドメインとユーザー名は全て大文字に変換しておく
※文字列のNULLターミネーションは不要(含めない)
サーバから(CHALLENGE_MESSAGEの内容)
・Server challenge (8byte)
・TargetInfo (可変長)
(クライアント側で)生成するもの
・タイムスタンプ(8byte)
・Client challenge (8byte乱数)
1.パスワードのmd4ハッシュを求める
2.ユーザ名とドメイン名を連結する(例:「user」+[Domain]→「USERDOMAIN」 )
※ここを先入観でDOMAIN+USERの順番だと思い込んでハマりました・・・
3.2に対して、1を鍵として、hmac_md5を計算する
4.以下を連結する(これをblobと言うらしい)
署名(固定値=0x01010000)
4byteの予約領域その1(0x00000000)
タイムスタンプ(8byte)
Client challenge(8byte)
4byteの予約領域その2(0x00000000)
TargetInfo
4byteの予約領域その3(0x00000000)
5.Server challengeと4を連結する
6.5に対して、3を鍵として、hmac_md5を計算する
7.6と4を連結する
7で出来たものがNTLMv2レスポンスになります。
ややこしいですね。
MD4はRFC 1320
MD5はRFC 1321
HMACは RFC 2104に規定されています。
なお、それぞれC言語コードが附属しています。
たいして計算量も無いので最適化も不要でしょうから、そのまま使ってもOKかと思います。ただしライセンス表記が必要です。
探せばそのあたりをクリアしたコードも見つかります。
(僕はmd4はそのまま使いました。md5は以前準備したコードがあったのでそっちを利用)
基本的に、SMBと同じく全てリトルエンディアンが使われます。
普通ネットワークバイトオーダーと言えばビッグエンディアンなんですけどね。
最初はエンディアン気にしてコード書いてましたが、どうせiPhoneもリトルエンディアンだし途中から面倒になってリトルエンディアン環境想定で作りました。
さて、これでSMBサーバと認証ができるようになりました。
次回はWindowsファイル共有に使うNETBIOS名(ホスト名)をNetBIOS over TCP/IPを使って名前解決(IPアドレスを取得する)をやってみたいと思います。
まぁ、IPアドレスでアクセスすれば良いので不要な気もしますが。。
欲を言えばBROWSERプロトコルを使ってネットワーク上のNETBIOSホスト名を自動収集したいところですが、、まぁNASとかはBonjourに対応してるから不要な気もします。
2015-05-18 修正 challengeのスペルが違うというお恥ずかしいミスがありましたのでこっそり修正。
