Posted on 2014年9月8日(月) 23:53
UTF-8って素晴らしいですよね。
unicodeは元々、世界中の全ての文字を16bitで表現するという英語圏以外の人からすればあまりに愚かな試みからスタートしましたが、もちろん破綻。
16bitを使いながら、サロゲートペアを使って16bit以上のコードも表現するようになりました。
結局サロゲートペアが必要な時点でUTF-16は欠点ばかりのものとなってしまいました。
最近よく使われるのはUTF-8です。ASCIIコードと互換性が保ちやすく大変便利ですね。
UTF-8は結局のところUTF-32をシリアライズしただけのものなんですが、へぇよく考えてるなぁという感じなのです。
任意のバイトストリームから混同せずに文字列を取り出せます。
ただ欠点もあって、色々処理をするときに文字ごとに長さが違うので厄介です。
そこでUTF-8から32bit表現(UTF-32)に変換するコードを書いてみました。
プログラムの内部的にはUTF-32を使うと捗りますので。
このようなUTF-8の欠点はサロゲートペアがある時点でUTF-16でも同様なんですが、サロゲートペアはあまり出てこないので無視してしまってる駄目な処理系もあるような気がします。
なお、セキュリティの観点からはUTF-8の冗長表現が問題になることもあります。
本来ASCIIコードである文字でももっと大きなバイス数で表現することが出来てしまうので不正文字チェックを抜けてしまうということです。
例えば0xC0 0xAF(11000000 10101111)は、2バイトのUTF-8として扱うと[101111]の部分がデータになりますので、0x2F(バックスラッシュ)と等価になります。
つまりより小さいバイトのコードは大きなバイト数でも表現出来てしまうため、単純チェックだとすり抜けるということです。
仕様ではこのようなバイト列は不正なUTF-8バイト列としなければなりません。
また5バイトと6バイトのUTF-8も現在ではUnicodeとしては不正とされていますがISO/IEC 10646では存在しています。
以下のコードではそのような不正なUTF-8もそのまま変換します。
unsigned long utf8ToUtf32(unsigned char *input, int *bytesInSequence)
{
unsigned char c1, c2, c3, c4, c5, c6;
*bytesInSequence = 1;
if (!input)
{
return 0;
}
//0xxxxxxx (ASCII) 7bit
c1 = input[0];
if ((c1 & 0x80) == 0x00)
{
return c1;
}
//10xxxxxx high-order byte
if ((c1 & 0xc0) == 0x80)
{
return 0;
}
//0xFE or 0xFF BOM (not utf-8)
if (c1 == 0xfe || c1 == 0xFF )
{
return 0;
}
//110AAAAA 10BBBBBB 5+6bit=11bit
c2 = input[1];
if (((c1 & 0xe0) == 0xc0) &&
((c2 & 0xc0) == 0x80))
{
*bytesInSequence = 2;
return ((c1 & 0x1f) << 6) | (c2 & 0x3f);
}
//1110AAAA 10BBBBBB 10CCCCCC 4+6*2bit=16bit
c3 = input[2];
if (((c1 & 0xf0) == 0xe0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80))
{
*bytesInSequence = 3;
return ((c1 & 0x0f) << 12) | ((c2 & 0x3f) << 6) | (c3 & 0x3f);
}
//1111 0AAA 10BBBBBB 10CCCCCC 10DDDDDD 3+6*3bit=21bit
c4 = input[3];
if (((c1 & 0xf8) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x07) << 18) | ((c2 & 0x3f) << 12) | ((c3 & 0x3f) << 6) | (c4 & 0x3f);
}
//1111 00AA 10BBBBBB 10CCCCCC 10DDDDDD 10EEEEEE 2+6*4bit=26bit
c5 = input[4];
if (((c1 & 0xfc) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80) &&
((c5 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x03) << 24) | ((c2 & 0x3f) << 18) | ((c3 & 0x3f) << 12) | ((c4 & 0x3f) << 6) | (c5 & 0x3f);
}
//1111 000A 10BBBBBB 10CCCCCC 10DDDDDD 10EEEEEE 10FFFFFF 1+6*5bit=31bit
c6 = input[5];
if (((c1 & 0xfe) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80) &&
((c5 & 0xc0) == 0x80) &&
((c6 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x01) << 30) | ((c2 & 0x3f) << 24) | ((c3 & 0x3f) << 18) | ((c4 & 0x3f) << 12) | ((c5 & 0x3f) << 6) | (c6 & 0x3f);
}
return 0;
}
Posted on 2014年7月17日(木) 03:04
Snow Leopardの次から色々と断絶があり、現在のxocdeでSnow Leopard以前で動くバイナリを作ることは出来ません。
iOSについても同様で、iOS4.x以前向けのSDKは現在のxcodeには含まれていません。
もう無視していいかなーと思っていましたが、今だに必要になったのでメモ。
必要なもの
・Mac(MacOSX のバージョンは新しいものでOK)
なお、Snow Leopardが動くMac実機が用意できれば何の問題もありません。普通にそれ使って下さい…。
・Snow Leopardのインストールディスク
・Xcode4.2のインストーラ
Xcode4.2の入手方法
Xcode4.2を入手する方法について困る方がいらっしゃると思います。
Xcode4.2をダウンロードしたことがあるAppleアカウントがあればAppleのサイトから再ダウンロードできます。
(Downloads for Apple Developersのページにて”Xcode 4.2″で検索)
Xcode4.2を購入した事があるか、当時有償で開発者登録しておりXcode4.2をダウンロードしたことがある場合は何の問題もなく再ダウンロードできると思いますが新規アカウントなどでは検索しても出てきません。
実はXcode4は600円の有償販売でした。よって今でも無料ダウンロードは出来ないということになっているようです。
しかも今はもう買えません・・・。
勝手にXcode4.2のインストーラを置いているサイトがあるかもしれませんが、それは違法コピーということになりますのでご注意ください。
アップルさんにはこの際無償公開して欲しいところです。せめて再販売・・・。
現在の環境構築手順
1.VirtualBox(無料)をダウンロードしてMacにインストール
MacはMarvericksで大丈夫です。
2.仮想マシンにSnow Leopardをインストール
特に気をつけることはなく普通にインストールできます。
ちなみにWindowsでやろうとしても無理ですし、ライセンス的にもNGです。
3.Downloads for Apple Developersのページにて”Xcode 4.2″で検索
・・・ここでXcode4.2が出てこなかった方。
大変残念ですが、ログインしているアカウントではXcode4.2はダウンロードできません。
4.Snow LeopardにXcode4.2をインストール
・・・「インストールが失敗しました」。となる場合はソフトウエアアップデートをかけてください。
Appleインストーラの更新がこの時期にかかっており、アップデートしないとインストールに失敗します。
以上です。
新しいxcodeのプロジェクトをXcode4.2で開いたりするとぶっ壊れますのでご注意ください。
また、Xcode4.2で使っていたプロジェクトを新しいXcodeで開いてしまうと、二度とXcode4.2では開けなくなりますのでご注意ください。
Posted on 2014年3月23日(日) 02:03
かつて、LinuxからSambaを使ってWindowsのファイル共有にアクセスすると、文字コードの変換の問題で大変苦労しました。
時代は流れ、LinuxでもWindowsでもUnicodeが標準になりました。
というわけで、一般的にSMBを使う分には文字コードで苦労することはほぼなくなりました。
しかし・・・。
とりあえず以下の画像をご覧ください。
これはWindows8のエクスプローラーの画面です。
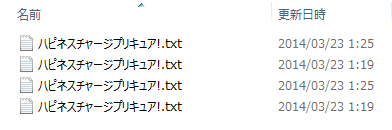
何かおかしいところにお気づきでしょうか。
おかしいですよね。
いいおっさんがプリキュア・・・じゃなくて、同一のファイル名が同じフォルダに存在しています。
実はこれ、「ピ」と「プ」の文字がUNICODEの結合文字列になっています。
通常、Windowsで「プリキュア」と入力した場合、「プ」の文字はU+30D7になります。
しかしMacOSで「プリキュア」と(ファイル名として)入力した場合、「プ」の文字はU+30D5 U+309Aになります。
U+30D5は「フ」です。
U+309Aは半濁点記号です。
つまり、「フ」+「゜」の合成で表現されます。
(なお、ここに書いた「゜」はU+309Cで、合成用ではなくそういう1文字ですので念のため)
Unicodeではこのような複数の表現方法があります。
混ざってる何かと困るので、普通は同一コードになるように正規化して扱います。
合成した方を使うのをNFC(Normalization Form Canonical Composition)、分解した方を使うのをNFD(Normalization Form Canonical Decomposition)と言います。
さて、最初の画像のファイル名ですが、「パ」と「プ」の表現方法を結合文字列、合成文字、混ぜてあります。
結果として4パターンの同名ファイル名が出来てしまったわけです。
何故かWindowsは上記のような状態を許してくれます。
許しているというか、初期の頃になんの正規化もせず扱ってしまったため、以後もそのままになっているんだと思います。(憶測)
さて、一方MacOSですが、上記のようなNFD,NFCの混在を許してくれません。
必ずNFDライクな正規化をされます。(正確にNFDでないのがまた困るんですが・・・)
iOSも一緒です。
よってファイル共有をすると大変困ります。
SMBには明確な仕様がない(もしかしたらあるかもしれなけど、ドキュメント読む限り発見できず)。
おそらくWindowsなのでNFCのUTF16 Little endianなんでしょうが、NFDでもプロトコルとしては問題なく(というかノータッチで)動きます。
さて、どう実装するのが正解なのでしょうか。
困りました。
Posted on 2013年12月19日(木) 00:56
Windowsで使われる、NetBIOSまわりを頑張ってみます。
やりたいことは、Windowsコンピュータ名(NETBIOS名)からIPアドレスを取得することです。
NetBIOSはとにかく不可解です。
本当に不可解なんですが、歴史的背景があるので仕方がありません。
どのくらい古いかというと1980年代くらいなので仕様書もイマイチ読みづらく、後の改変も多数あるので本当にわかりづりです。
まずNetBIOSはTCP/IPとは別物です。
現在ではプロトコル部分をNetBEUI、インターフェイス部分をNetBIOSと呼ぶようですが、元はインターフェイス(API)からプロトコルまですべてひっくるめた規格でした。
NetBEUIは現在では使われることは無くなりましたが、NetBIOSのインターフェイスだけは利用され続けているというわけです。
NetBIOSをTCP/IPで利用できるようにしたものがNetBIOS over TCP/IPです。(TCP/IPとか言いながらUDP/IPも多用します)
これ時代もWindows3.x時代のものなので何かと理解しづらいです。
さて、関係ありそうな、NetBIOS over TCP (NBT) Extensions NetBIOS over TCP (NBT) Extensions[MS-NBTE]をまず見てみると
名前解決についてはRFC1002を見るように書いてあります。
RFC1002の内容は「NetBIOS-over-TCP」となっています。
日付は March 1987・・・。
読んでみると・・・なんか意味不明・・ですががんばって読む。
とりあえずパケットのフォーマットはこう
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NAME_TRN_ID | OPCODE | NM_FLAGS | RCODE |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| QDCOUNT | ANCOUNT |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NSCOUNT | ARCOUNT |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
で、名前解決のリクエストはこういう固定値を入れる
4.2.12. NAME QUERY REQUEST
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NAME_TRN_ID |0| 0x0 |0|0|1|0|0 0|B| 0x0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x0001 | 0x0000 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x0000 | 0x0000 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
/ QUESTION_NAME /
/ /
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NB (0x0020) | IN (0x0001) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Bはブロードキャストフラグなので、1で固定みたいです。
なのでフラグ部分は0x0110。
QUESTION_NAMEの部分はRFC 883を使ってコード化しろって書いてます!
これがまだ何故??というやり方で頭に???浮かびっぱなしです。
とりあえずNETBIOS名は15文字です。本来は16文字でしたが、最後の1バイトを別の用途に割り当てたため15文字。
15文字に満たない場合はスペース(0x20)で埋めます。
16文字目はサフィックスで種別を表すのですが、
0x00だとワークステーション サービス
0x20だとファイル サーバー サービス
0x1bだとドメイン マスタ ブラウザ
・・・などなどを表すようですが、、
これはもともとのLAN Managerの仕様ではなくMicrosoftの拡張仕様です。
どうやら0x00はクライアント、0x20がサーバサービスを示すようなのでここでは0x20が正解だと思われます。(実際にはどちらも名前登録されていて、反応もしてくれるので良いのですが)
で、肝心のNETBIOS名の格納方法です。
最初の1バイトは0x20を指定します。0x20=長さが32byteの意味で、NETBIOS名の場合は32byte固定と書いてあるので必ず0x20を指定。
NEBIOS名+サフィックスの16byteを以下の手順で符号化して32Byteにします。
最後にNULL(0x00)くっつけるので、長さを表す先頭の0x20と合わせて34byteになります。
これがQUESTION_NAMEになります。
NETBIOS名の符号化は、
まず文字コードを4バイト単位にわけます。
空白文字(0x20)であれば0x2と0x0です。
0x0をA、0x1をB、0x2をC・・・という感じで文字を割り当てます。
0x20であれば「CA」になります。
つまりNETBIOS名が「FRED」であれば「EGFCEFEECACACACACACACACACACACACA」になります。
さて、これをUDPでブロードキャストすれば該当ホストがレスポンスを返してくれます。
iOSで1024番以下のポートをbindできるのか?とちょっと不安でしたが、やってみたら大丈夫でした。
レスポンスの内容は以下のとおり
4.2.13. POSITIVE NAME QUERY RESPONSE
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NAME_TRN_ID |1| 0x0 |1|T|1|?|0 0|0| 0x0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x0000 | 0x0001 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x0000 | 0x0000 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
/ RR_NAME /
/ /
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NB (0x0020) | IN (0x0001) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TTL |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| RDLENGTH | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
| |
/ ADDR_ENTRY ARRAY /
/ /
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
TTLより前はリクエストと同じ。
ADDR_ENTRY ARRAYにIPアドレスが入ります。
(複数ある場合は複数入ります。パケットの送信アドレスを見るか、自分のネットワークマスクと較べてどれを利用するか決めます)
実際には名前の解放パケットとかも飛んでくるようですが(それを見てキャッシュから削除する)、iOSでそれを監視し続けるのは非現実的なので無視します。
なお、IPv6の場合はLLMNR(Link-Local Multicast Name Resolution)を使う必要があります。
今回はIPv4だけでいいのでそっちはやりません。
(そのくらいの知識がある人はIPアドレスでわかるでしょうし・・・)
さて、これでコンピュータ名(NETBIOS名)を解決できるようになりました。
まぁ、なったところでどう使うかは悩ましいところなんですけどね。
Posted on 2013年12月13日(金) 02:23
Windows関連情報は運用を目的にしたものが多く、コーディング例はあんまり聞かないのでメモ的に書いておきます。
SMBの認証にはLM認証、NTLMv1認証、NTLMv2認証、Kerberos認証のいずれかを使います。
Kerberos認証は鍵交換でActiveDirectly環境想定のものなので除外。
LM認証はNTLMv1認証はだいぶ古いにもかかわらずつい最近まで使われていましたがWindows7からはデフォルト無効になっているようなのでこちらも使わない方針で行きます。
ようするに面倒なのでNTLMv2だけ対応します。
あと、まず非対応ということはあり得ないので、Unicodeだけ対応します。
さて、NTLMは「NT LAN Manager Authentication Protocol」のことらしいです。
Microsoftの仕様書名は[MS-NLMP]です。
基本的には認証情報をバイト列に並べているだけなので仕様書を読みながら実装すればなんとか出来ます。
SMB/CIFSがアライメントやら謎のpaddingやらとても実装しにくいのに比べると可変長データをpayloadにまとめているので少しだけ気楽です。
クライアント側で生成する必要があるのは、NEGOTIATE_MESSAGEとAUTHENTICATE_MESSAGEです。
前者は本当に必要な情報を連結してバイト列にしているだけなので楽勝。それでも実際実装してみると一発ではなかなか思い通りにならないのですが・・・。
後者のAUTHENTICATE_MESSAGEもほとんど同じですが、NEGOTIATE_MESSAGEに対してサーバから返されたCHALLENGE_MESSAGEに含まれる情報を使ってチャレンジレスポンスを計算する必要があります。
それがNTLMv2なわけですね。
AUTHENTICATE_MESSAGEのうち、計算が必要なのはNTLMv2 Responseというフィールドです。
といっても、使うのはmd4とmd5だけなんですね。
試行錯誤の結果正しい結果を出せるようになったのでメモ。
入力
・ドメイン(大文字のみ,UTF16LittileEndian)
・ユーザ名(大文字のみ,UTF16LittileEndian)
・パスワード(UTF16LittileEndian)
※ドメインとユーザー名は全て大文字に変換しておく
※文字列のNULLターミネーションは不要(含めない)
サーバから(CHALLENGE_MESSAGEの内容)
・Server challenge (8byte)
・TargetInfo (可変長)
(クライアント側で)生成するもの
・タイムスタンプ(8byte)
・Client challenge (8byte乱数)
1.パスワードのmd4ハッシュを求める
2.ユーザ名とドメイン名を連結する(例:「user」+[Domain]→「USERDOMAIN」 )
※ここを先入観でDOMAIN+USERの順番だと思い込んでハマりました・・・
3.2に対して、1を鍵として、hmac_md5を計算する
4.以下を連結する(これをblobと言うらしい)
署名(固定値=0x01010000)
4byteの予約領域その1(0x00000000)
タイムスタンプ(8byte)
Client challenge(8byte)
4byteの予約領域その2(0x00000000)
TargetInfo
4byteの予約領域その3(0x00000000)
5.Server challengeと4を連結する
6.5に対して、3を鍵として、hmac_md5を計算する
7.6と4を連結する
7で出来たものがNTLMv2レスポンスになります。
ややこしいですね。
MD4はRFC 1320
MD5はRFC 1321
HMACは RFC 2104に規定されています。
なお、それぞれC言語コードが附属しています。
たいして計算量も無いので最適化も不要でしょうから、そのまま使ってもOKかと思います。ただしライセンス表記が必要です。
探せばそのあたりをクリアしたコードも見つかります。
(僕はmd4はそのまま使いました。md5は以前準備したコードがあったのでそっちを利用)
基本的に、SMBと同じく全てリトルエンディアンが使われます。
普通ネットワークバイトオーダーと言えばビッグエンディアンなんですけどね。
最初はエンディアン気にしてコード書いてましたが、どうせiPhoneもリトルエンディアンだし途中から面倒になってリトルエンディアン環境想定で作りました。
さて、これでSMBサーバと認証ができるようになりました。
次回はWindowsファイル共有に使うNETBIOS名(ホスト名)をNetBIOS over TCP/IPを使って名前解決(IPアドレスを取得する)をやってみたいと思います。
まぁ、IPアドレスでアクセスすれば良いので不要な気もしますが。。
欲を言えばBROWSERプロトコルを使ってネットワーク上のNETBIOSホスト名を自動収集したいところですが、、まぁNASとかはBonjourに対応してるから不要な気もします。
2015-05-18 修正 challengeのスペルが違うというお恥ずかしいミスがありましたのでこっそり修正。
Posted on 2012年11月6日(火) 23:48
URLをパーセントエンコーディングするとき、stringByAddingPercentEscapesUsingEncodingを使ってはいけないという記述をよく見ますが、用途次第です。
このメソッドは「$&+,/:;=?@」をエンコードしてくれません。
しかしこれが逆に必要な時もあって、具体的には非アスキーなURLをエンコードする場合です。
例えば以下のようなURLですね。
http://exmple.com/日本語/index.html
このURLはこのままだとNSURLなどに渡せません。
日本語部分をエスケープする必要があります。
しかしながら「/」や「:」までエスケープしてしまってはURLでなくなってしまいます。
stringByAddingPercentEscapesUsingEncodingはこのような時に使います。
「$&+,/:;=?@」は日本語まじりの場合でも必ずエスケープしないとURLの構成要素と区別がつきませんのでエスケープされているが、その他の非ASCII文字はエスケープされていないというような場合に利用できるわけですね。
どこで出現するかと言えば、NSURLConnectionなど使って通信しているとホスト側からリダクレイとされたりしたときに返ってくることがあります。
Posted on 2012年4月26日(木) 12:31
iOSでは通常の画像(image.png)と、解像度が倍のRetina用画像(image@2x.png)を両方用意しないといけませんが、すごく面倒です。
そこでimage@2x.pngを入れるとimage.pngを自動生成するアプリケーションを作ってみました。
奇数の大きさを持つファイルや@2xが名前についていないファイルは何もしません。
また、既にファイルが存在している場合は上書きします。
縮小は4画素を平均して1画素を作る方法で計算しています(画素平均法)。
輝度の端数は切り捨てです。
png画像のみ対応。需要があればjpegも対応しますが、ひとまずこれで。
ダウンロード
何かありましたらコメントかtwitter(@rhotta)までお願いします。
Posted on 2012年4月2日(月) 22:12
MacOSX(Lion)上で、NSImage – initWithContentsOfFileで画像ファイルを読み込んだ時、ファイル名に@2xがついているとNSImage.sizeの大きさが半分になっていることがある怪現象に遭遇しました。
ルールはわかりませんが、@2xがついていても半分にならないときもあり、すごい謎。
iOSで使うUIImageならば、@2xが付いているとRetina用画像ということで解像度倍なのですが、MacOSにはRetinaという概念はないはずなので@2xというファイル名で何かが変わるのは変だと思うのですが・・・。
なお、下記のようなコードでCGImageからサイズを取得すると正しいサイズが取得できます。
+ (NSSize)getImageSize:(NSImage*)image{
CGImageRef cgImage = [image CGImageForProposedRect:nil context:nil hints:nil];
NSSize imageSize;
imageSize.width = CGImageGetWidth(cgImage);
imageSize.height = CGImageGetHeight(cgImage);
return imageSize;
}
という事はつまり、UIImageで言うところのscaleが2.0になっている、という事なのでしょうが、NSImageにはscaleプロパティが無いのでわかりません。
噂のRetinaMacOSXへの布石なのか、ただのバグなのか、はたまた僕の理解不足なのかわかりませんが、とにかく謎です。
分かる方いらっしゃいましたら教えて下さい。
環境はMacOS SDK 10.7,MacOS Lionです。
