Posted on 2015年7月7日(火) 04:29
最近「ComicGlassのソートがWindowsの並びと違う」とご意見を頂きました。
WindowsXP以降ではファイル名のソート順が数値などを解釈する自然な並びになるようになっています。
よって単純なコードの比較とは違う結果になります。
よく説明されるのは、
20string
2string
3string
というソート順だったのが
2string
3string
20string
という感じになることでしょうか。
WindowsであればStrCmpLogicalW()というAPIを呼び出すとこのソートが行われます。
Windows以外の環境でこのソートを再現する方法は、検索するといくつか提案されていますが、どうも結果が違います。
公式な仕様が見つかればいいんですが、どうも見つかりません。
そこで、それを再現すべくそもそもWindowsがどのようにソートしているか実験してみました。
(特に海外のサイトの情報はUnicode文字に関する配慮がほとんどされてない事が多いので)
結論から言うと、StrCmpLogicalWを再現するのって無理ゲーなんじゃないかと・・・。
いい方法あったら是非教えてください。
とりあえず、以下調査結果でございます。
・StrCmpLogicalWは記号、数値、その他文字の順で並ぶ
ASCIIやUnicodeでは「!」は「0~9」より前にあるが「;」などは数値より後です。
しかしながらWindowsでは「;」などの記号も数値より前に並びます。
(Unicodeコード順)
!test.txt
0test.txt
;test.txt
(Windows)
!test.txt
;test.txt
0test.txt
というわけで、その文字が「記号」であるか「数値」であるか「その他文字」であるかを区別しているようです。
そこで問題になるのが、何が記号で何が記号でないか。
(記号になる例)
!
;
®
µ
§
»
★
(記号にならない一例)
¼
À
うーん。規則性がわからん。
プログラムを組んでStrCmpLogicalWで実際に試してみたのですが、かなり後ろの方のコードまで記号扱いになるものとと文字扱いになるものが入り乱れています。
どうもUnicodeコンソーシアムが規定するUNICOD文字一覧表に記号かどうかの情報があるようです。
つまりUnicodeとして記号かどうかで判断されており、それは規則性などなく全一覧を知らないとどうにもならない。
まぁ、それだけなら全コードの情報を持っておけばいいのですが・・・
・・・しかし!
Windowsが知らない新しいUnicodeは正しく解釈していないような気がします・・・。
例えばU+2639(☹)、U+263A(☺)、U+263B(☻)は記号扱いですが、その他顔文字は記号になりません。
もしかしたらWindowsではサロゲートペアが正しく処理されていないだけかもしれません・・・。
これは心が折れますね・・・!
・StrCmpLogicalWは全角の記号も半角と記号と同じ扱いになる
同じ記号の場合は全角の方が後になる。
・・・ってことは正準等価性を使った正規化してるんでしょうかね?
その説を支持する結果として「»」が「§」よりも前に並ぶんですよね。コードは後ろなのに。
しかし後述しますが、数値で混在すると別々に評価されるっぽい。つまり単純に先に正規化しても駄目と・・・。
・StrCmpLogicalWは数字が並んでいる場合はまとめて1つの意味付けがされる
0001.txt
2.txt
003.txt
これはファイルに0から順に名前つけて桁が増えた時に変な順番になるのを防げます。
・StrCmpLogicalWは20桁以上の数値は数値として扱わない
符号なし64bitで表せる値の最大値は18,446,744,073,709,551,616で20桁なので、20桁目からオーバーフローします。
よって、Windowsも64bit演算で扱える最大値の19桁まで取り扱うようになっていると思われます。
これは実装が楽で助かります。
・StrCmpLogicalWは全角の0~9も数字として扱われる
・ただし半角全角混在の場合はそうならない。何故だ・・。
情報求む・・・・!
とりあえずASCIIコードにある記号だけ記号として解釈し、数値は19桁まで数値として認識する、という方法でだいたい近い結果にはなります。一致はしませんが。
Posted on 2015年7月6日(月) 23:16
娘が小学校1年生になりました。
どうも「算数」って苦手・・
娘が納得しなかった問題で、
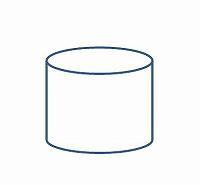
”(これを)よこから みると しかくに みえるね!”という男の子が出てくるのですが娘はこれに納得しないのです。
「四角にはならない」と言うのですが・・・うん、僕にも四角には見えない。
円柱は立体物で、「四角に見える」とか「円に見える」と言うには平面に投影した結果を言っています。
3次元の形状を2次元に投影する方法はいくつかありますが、目でみる場合には「透視投影」を行うことになります。
要するに遠くのものは小さく見えるし、近くのものは大きく見えます。
つまり、、、
円柱を描いてみます。
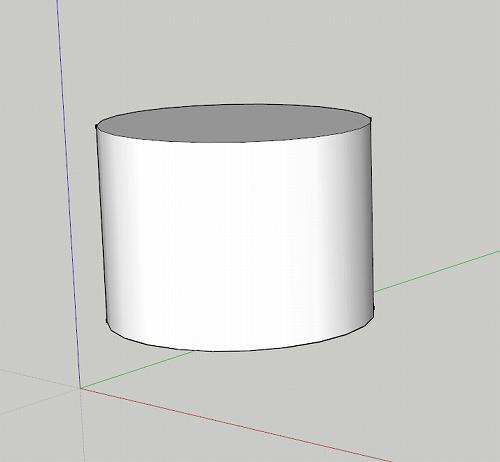
視点を変換して横から見てみます。
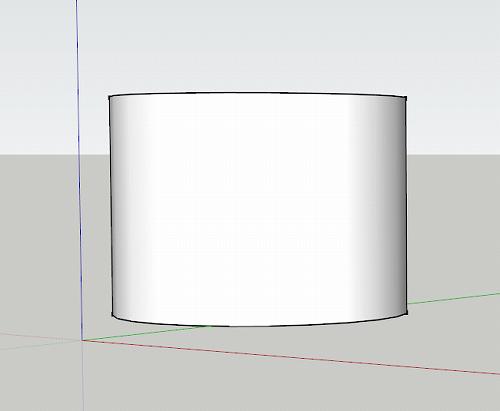
四角じゃない。
これが四角に見えるためには無限の距離から見なければなりません。もちろん無限の距離にあるものなんて大きさが限りなく0なので見えません。
図面のように平行射影すれば円柱の側面は四角に見えるかもしれませんが、目で見たら絶対四角にはならないんですよね。
おそらく問題の意図としては正射影したらどんな形かと言いたいんだとは思いますが、正射影を説明するのも難しいし・・と思ったけど、「遠くから見たら四角っぽくなるでしょ」というファジーな説明でなんとなく理解してくれたみたいです。。
うーん。算数やっぱり難しい。。
Posted on 2015年3月3日(火) 23:39
カードダスといえば、1998年から展開しているバンダイのトレーディングカードで、ちょうど僕が小学生くらいの時に出てきた覚えがあります。
2005年からはバーコードが印刷され、お店の筐体(ゲーム機じゃなくてカード販売機という事で風営法を逃れているらしい・・)(追記:←嘘です)でゲームと連動するデータカードダスが展開されています。
最初のタイトルはドラゴンボールだったような気がします。
プリキュアシリーズやアイカツはだいぶカード種類が多いと聞きます。
想定外に売れて、妖怪メダルのように割り当て固有番号が不足するんじゃないかと不安になります。
玩具のコードって徹底的に省略されてるじゃないですか。
さて、頑張ってシンボルを解読するぞー!
と思ったんですが、どうもコレCODE128の既存の規格そのままですね。
シンボルを読んでみます。
以下のようになります。

数値でいうと、103,33,43,20,18,17,55,43,40,46,53になります。
103はCODE Aの開始、つまり英数+制御コードでキャラクタが構成されることを示します。(小文字含まず)
53はチェックサムですね。
計算すると確かに53になります。
最後のシンボルはSTOPシンボルです。
というわけで、このカードの固有IDはAK421WKHNです。
ちなみにカード名称は「ピンクトルテシューズ」(星宮いちご)
本当に固有記号としての意味しかないようです。ただし最初のAKはアイカツを表しているようです。
iPhoneでバーコードを読み取るプログラムを書いてみました。
結果はこんな感じ。

実はorg.iso.Code128をセットすると、iOS標準のライブラリで認識可能。数行で実装できます。。
CODE128には、コードA~Cまでの文字セットがあります。
コードAは英数字+制御文字、コードBはASCIIのみ、コードCは数字のみ。
というわけで、DCDではコードAで記録しているようです。
データ領域は英数字で9文字分ということになります。
最初の2文字はコンテンツの種類を表しているようで、アイカツ!の場合は”AK”から始まります。
ちなみにプリキュアは”PR”のようです。まぁ、なんとなく理解できる記号ですね。
バーコードのデータ9文字から”AK”の2文字を引くと残りは7文字です。
このあたりで、もう表題に書いたことは無かったことにしたい感じですが、、
とりあえず英数字のみで割り当てるとします。
そうすると、アルファベット26文字+数字10文字の36通り×7桁なので、78,364,164,096 種類のカードを発行できることになります。
つまり780億種類以上なので、カード側の固有記号が枯渇することは全く持ってありませんね…。
AKの部分に新たな記号を追加することだって出来るわけですし。
そういえば前期プリキュアのプリカードは、パッと見ても嫌な予感のする変な切り込みがありますね。
これはたぶん玩具で読み取りを意識した、本当に省略されたコードだったと思われます。
妖怪ウォッチ ともだちウキウキペディアはどうやらQRコードに変わってるようですね。
Posted on 2014年10月24日(金) 01:00
タイトルのとおり。
どうも、Windows相手にNetBIOSの名前解決を試みると失敗することがあるようです。
ネットワーク・アナライザで見ると、リクエストは飛んでるのに応答が来ない。
発生条件は不明ですが、テストで変なリクエスト送ったあとに起きやすい気がするけど、何もしてなくても起きる時もある。
理由は不明ですが、一旦失敗するようになると、特定のIPアドレスから発信したものに対して応答が返らなくなる模様・・・。
全くそのままでIPアドレス変えると動くようになります。
このあたりエラーメッセージを簡略化してたので(接続できませんでしたくらいに)、次からメッセージ入れようと思います。
基本ここで失敗はしないと思っていたので。
どうもSMB/CIFS周りはロバスト性に欠けてやっかいですわー。
Windows同士でも調子わるいときありますもんね。
無駄にSMB/CIFS周り(のバッドノウハウ)に詳しくなっていく・・・。
Posted on 2014年10月10日(金) 21:00
ネットワークプログラミングの基本中の基本。socket()関数があります。
(基本すぎて今ではもう直接使う人はいないのかもしれませんが僕は使います。。)
socket()関数は戻り値としてソケットのファイル・ディスクリプタを返します。
このソケットのファイル・ディスクリプタが何故か現代人には勘違いしやすいようで、うっかり0をエラー値だと思い込んでしまいます。socket()はエラーが発生したときには-1を返します。
これがうっかり間違えます。実際0が返ってくることがありますのでたまに動かないという分かりにくい不具合の原因になります。
わかっているのにうっかり間違えた例が以下のような感じです。本当に良く見かけます。自分も間違えますが・・・。
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd <= 0) {
// COV_NF_START - we'd need to use up *all* sockets to test this?
startFailureCode = kGTMHTTPServerSocketCreateFailedError;
goto startFailed;
// COV_NF_END
}
おそらくポインタを返す時の失敗はNULLだろう、ハンドルを返すときのエラーは0だろう的な思い込みがあるせいではないかと思います。
WindowsのAPIは成功すると非ゼロを返すという仕様のものが多いので、そういう普段使っている環境での慣れもあるのかも・・・。
ちなみに上記のコードはGoogle Toolbox for Macの一部にありました。
同様に
if(soc){
close(soc);
}
みたいなミスもうっかりやりがちなのでお気をつけください。
Posted on 2014年9月30日(火) 23:40
・・・タイトルのようなソフトをリリースしましたのでお知らせします。
リリースしたのは少し前ですが、記事にしていませんでしたので。
最近のWindowsではソフトウエアでボリュームのミラーが作れるようになり、HDDの故障に備えることができるようになりました。
Windowsのミラーの良いところは何より扱いやすいことです。BIOS画面一切さわる必要ありませんし。
しかし、いざ障害が起きた時にそれを知る手段がイマイチないのが問題でした。
というわけでステータスが変わったらメールするソフト作ってみました。
こちらでございます。
http://arinkosoft.com/download/asvolumestatuschecker/
Posted on 2014年9月19日(金) 20:14
iOS8対応にあたり苦労する箇所、問題になった箇所です。
iOS7以降からのアプリの移植に際するものです。
最初からiOS8だけ考えるなら苦労することはありません。
間違ってもこれからiOS7も対応しよう! なんて無駄なことはしないことです。。
まずiOS8は見た目はあまり変わっていないにも関わらずメソッドやクラスの廃止、仕様変更がかなり大胆に行われています。
これはiOS3以降、過去をみても最大規模じゃないかと思います。
(どの程度影響するかはアプリによって違うので個人的感覚になりますが)
しかも苦労して対応しても使い勝手が良くなるような性質のものじゃないのが主です。うわー。
犯人はswiftだと思います。swiftから使いやすいように古い設計のものを一新したんだと思います。
画面の回転
まず最大の難所は画面の回転周りが大幅に仕様変更になったことです。
メソッドの廃止とか生易しいレベルではなく、座標系が変わりました。
例えばUIScreenが返す画面サイズの仕様が変わり、画面の回転に応じてサイズが変わるようになりました。
それに関連して、UIWindowが勝手にサイズが変わるようになり、しかも座標軸まで変わりました。
(以前はUIWindowは回転せず、Viewが回転していました。iOS8からはUIWindow自体が回転&サイズ可変になりました)
デバイスが横向きの時の座標軸を図にしたものがこちら。
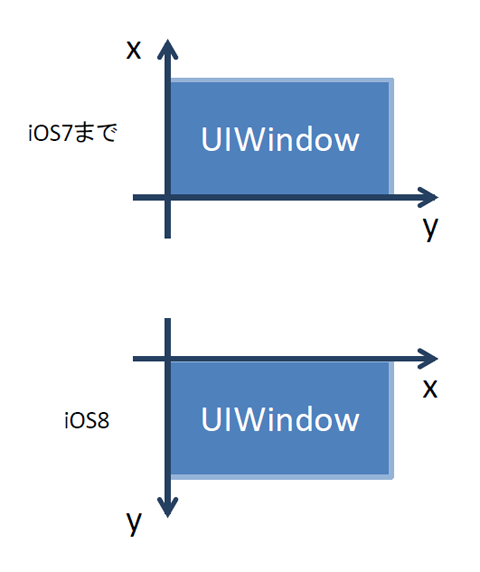
このあたりはアプリがどのように作られていたかにもよりますが、場合によっては大幅に修正が必要になり相当苦労すると思います。
特にviewよりも深いところを使っていると悲惨。
特にiOS7以前もサポートし続ける場合はアプリ内で複数の座標系が存在するという地獄絵図に・・・。
僕もアプリは回転する画面が50個以上あり、UIWindowに直接Viewを貼ったりしていたので見事悲惨でした。
更にinterfaceOrientationなどもdeprecatedになっており、これまでと違う設計を強いられます。
回転という概念から、リサイズという概念に変更されているようなイメージです。
UIViewControllerからはデバイスの向きを取得できなくなりました。
どうしても取得したければUIApplicationのstatusBarOrientationがかろうじて使えます。よかった・・。
UIAlertView、UIActionViewの廃止
馴染み深いこの2つがdeprecatedになっています。
UIAlertControllerに置き換えることになります。
たぶん大量に使っているのでひどい目似合います。
また、このUIAlertController、ボタンを押した後の反応が悪いです。
詳しく言うとアニメーションが終わってからしかActionが呼ばれません。
以前はボタンを押した時、Viewが消えた時と順次イベントが発生しましたので時間のかかる処理は先に実行しておくことができました。
個人的には大問題だと思いますので、もう自分で実装しようかな・・・。(時間が出来た頃に)
また、iPadではActionSheetが矩形を指定してそっからポップオーバーするようになりました。
矩形位置を指定しないといけなくなり、これまでの実装からの移植は苦労すると思います。
といって操作しやすいわけでもないし、上記のとおり遅いし・・・。うーん。なにこれ。
実はiOS8でもUIAlertView、UIActionView共に動作するので無視して使うという手もあるかもしれません。
UISearchDisplayControllerも廃止
なんでか分かりませんがUISearchDisplayControllerもdeprecatedです。
UISearchControllerを使うことになります。
別に特に便利でもなくめんどくさいです・・・。
UIViewControllerのもろもろタイミング変更
よくわかりませんが、viewDidLoadをはじめとする各種イベントの呼び出しタイミングが少し変わってます。
十分検証が必要です。
iPhone6 Plus
こいつはiPadなのかiPhoneなのかハッキリしろ的なもどかしさがあります。
というのもHOME画面が回転するなど、iPad的です。
起動時に横向きになっていることもあるわけで、このあたりiPadだけ区別して対応していたならば修正が必要になります。
あと画面大きすぎてシミュレータ表示できない。。。
Posted on 2014年9月19日(金) 16:24
とりあえず速報です。
iPhone6 Plus買いました。
でかいですね。
最初の設定時に気づいたのですが、「拡大モード」というのがあります。
シミュレータにはありませんでした。
その名のとおり、画面の要素全体が大きめになります。
アプリ側でそのような情報は来なかったと思うので、どのように対応しているかと思ったらピクセル数がiPhone6と同じになるようです。
さらにHOME画面も回転しなくなったりなど、まさにiPhone6のようになります。
よって、開発者はiPhone6PlusがあればiPhone6の解像度もテストできますよね。ステキ!
以下が検証結果です。
なんと!
iPhone6 Plusの拡大モードは、ピクセル数はiPhone6と同じですが、画面のscaleが@3x相当になってますね。
つまりまさかの新しいスクリーンサイズが今日新たに判明です! ステキ!
iPhone 6 シミュレータ
deviceName=x86_64
[UIScreen mainScreen].bounds=(375.000000,667.000000)
[UIScreen mainScreen].scale=2.000000
iPhone 6 Plusシミュレータ
deviceName=x86_64
[UIScreen mainScreen].bounds=(414.000000,736.000000)
[UIScreen mainScreen].scale=3.000000
iPhone 6 実機
deviceName=iPhone7,2
[UIScreen mainScreen].bounds=(375.000000,667.000000)
[UIScreen mainScreen].scale=2.000000
iPhone 6Plus 実機・標準モード
deviceName=iPhone7,1
[UIScreen mainScreen].bounds=(414.000000,736.000000)
[UIScreen mainScreen].scale=3.000000
iPhone 6Plus 実機・拡大モード
deviceName=iPhone7,1
[UIScreen mainScreen].bounds=(375.000000,667.000000)
[UIScreen mainScreen].scale=3.000000 ←New!
Posted on 2014年9月17日(水) 23:30
画面サイズの数字がよくわからなくなるので早見表作りました。
| Model |
論理サイズ |
物理サイズ |
物理/論理比 |
| widthxheight |
比率 |
近似 |
x1 |
x2 |
x3 |
Pixel |
| 4s以前 |
320×480 |
2:3 |
2:3 |
320×480 |
640×960 |
– |
640×960 |
1 |
| 5/5s |
320×568 |
40:71 |
9:16 |
– |
640×1136 |
– |
640×1136 |
1 |
| 6 |
375×667 |
375:667 |
9:16 |
– |
750×1334 |
– |
750×1334 |
1 |
| 6plus |
414×736 |
9:16 |
9:16 |
– |
– |
1242×2208 |
1080×1920 |
約0.870 |
| iPad |
768×1024 |
3:4 |
3:4 |
768×1024 |
1536×2048 |
– |
1536×2048 |
1 |
物理サイズはRetinaモデルのものを書いてます。
iPhoneのx1サイズは3GSが最後ですので、新しいOSのみに対応するなら無いものと考えてOKです。
iPadはiPad mini(初代)がx1です。
iPhone6 Plusのみ論理座標と物理ピクセル数に差があります。
5sを基準として座標を変換するために倍率を計算しました。
(将来に備えてこの数字を直接使うのではなく、内部で計算したほうが幸せになれるとは思いますが)
| Model |
横 |
縦 |
倍率 |
| 横 |
縦 |
だいたい |
| 5/5s |
320 |
568 |
1.0 |
1.0 |
1.0 |
| 6 |
375 |
667 |
1.171875 |
1.17429577465 |
1.173 |
| 6plus |
414 |
736 |
1.29375 |
1.29577464789 |
1.295 |
Posted on 2014年9月8日(月) 23:53
UTF-8って素晴らしいですよね。
unicodeは元々、世界中の全ての文字を16bitで表現するという英語圏以外の人からすればあまりに愚かな試みからスタートしましたが、もちろん破綻。
16bitを使いながら、サロゲートペアを使って16bit以上のコードも表現するようになりました。
結局サロゲートペアが必要な時点でUTF-16は欠点ばかりのものとなってしまいました。
最近よく使われるのはUTF-8です。ASCIIコードと互換性が保ちやすく大変便利ですね。
UTF-8は結局のところUTF-32をシリアライズしただけのものなんですが、へぇよく考えてるなぁという感じなのです。
任意のバイトストリームから混同せずに文字列を取り出せます。
ただ欠点もあって、色々処理をするときに文字ごとに長さが違うので厄介です。
そこでUTF-8から32bit表現(UTF-32)に変換するコードを書いてみました。
プログラムの内部的にはUTF-32を使うと捗りますので。
このようなUTF-8の欠点はサロゲートペアがある時点でUTF-16でも同様なんですが、サロゲートペアはあまり出てこないので無視してしまってる駄目な処理系もあるような気がします。
なお、セキュリティの観点からはUTF-8の冗長表現が問題になることもあります。
本来ASCIIコードである文字でももっと大きなバイス数で表現することが出来てしまうので不正文字チェックを抜けてしまうということです。
例えば0xC0 0xAF(11000000 10101111)は、2バイトのUTF-8として扱うと[101111]の部分がデータになりますので、0x2F(バックスラッシュ)と等価になります。
つまりより小さいバイトのコードは大きなバイト数でも表現出来てしまうため、単純チェックだとすり抜けるということです。
仕様ではこのようなバイト列は不正なUTF-8バイト列としなければなりません。
また5バイトと6バイトのUTF-8も現在ではUnicodeとしては不正とされていますがISO/IEC 10646では存在しています。
以下のコードではそのような不正なUTF-8もそのまま変換します。
unsigned long utf8ToUtf32(unsigned char *input, int *bytesInSequence)
{
unsigned char c1, c2, c3, c4, c5, c6;
*bytesInSequence = 1;
if (!input)
{
return 0;
}
//0xxxxxxx (ASCII) 7bit
c1 = input[0];
if ((c1 & 0x80) == 0x00)
{
return c1;
}
//10xxxxxx high-order byte
if ((c1 & 0xc0) == 0x80)
{
return 0;
}
//0xFE or 0xFF BOM (not utf-8)
if (c1 == 0xfe || c1 == 0xFF )
{
return 0;
}
//110AAAAA 10BBBBBB 5+6bit=11bit
c2 = input[1];
if (((c1 & 0xe0) == 0xc0) &&
((c2 & 0xc0) == 0x80))
{
*bytesInSequence = 2;
return ((c1 & 0x1f) << 6) | (c2 & 0x3f);
}
//1110AAAA 10BBBBBB 10CCCCCC 4+6*2bit=16bit
c3 = input[2];
if (((c1 & 0xf0) == 0xe0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80))
{
*bytesInSequence = 3;
return ((c1 & 0x0f) << 12) | ((c2 & 0x3f) << 6) | (c3 & 0x3f);
}
//1111 0AAA 10BBBBBB 10CCCCCC 10DDDDDD 3+6*3bit=21bit
c4 = input[3];
if (((c1 & 0xf8) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x07) << 18) | ((c2 & 0x3f) << 12) | ((c3 & 0x3f) << 6) | (c4 & 0x3f);
}
//1111 00AA 10BBBBBB 10CCCCCC 10DDDDDD 10EEEEEE 2+6*4bit=26bit
c5 = input[4];
if (((c1 & 0xfc) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80) &&
((c5 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x03) << 24) | ((c2 & 0x3f) << 18) | ((c3 & 0x3f) << 12) | ((c4 & 0x3f) << 6) | (c5 & 0x3f);
}
//1111 000A 10BBBBBB 10CCCCCC 10DDDDDD 10EEEEEE 10FFFFFF 1+6*5bit=31bit
c6 = input[5];
if (((c1 & 0xfe) == 0xf0) &&
((c2 & 0xc0) == 0x80) &&
((c3 & 0xc0) == 0x80) &&
((c4 & 0xc0) == 0x80) &&
((c5 & 0xc0) == 0x80) &&
((c6 & 0xc0) == 0x80))
{
*bytesInSequence = 4;
return ((c1 & 0x01) << 30) | ((c2 & 0x3f) << 24) | ((c3 & 0x3f) << 18) | ((c4 & 0x3f) << 12) | ((c5 & 0x3f) << 6) | (c6 & 0x3f);
}
return 0;
}
« 前のページ
次のページ »
